

Building agents is easy. Trusting them in production is not.
The real bottleneck isn't raw container execution speed, it's the outer loop: evaluating your agent against real historical context, fixing what broke, and redeploying with confidence. Today we're launching Chalk Compute to close that loop.
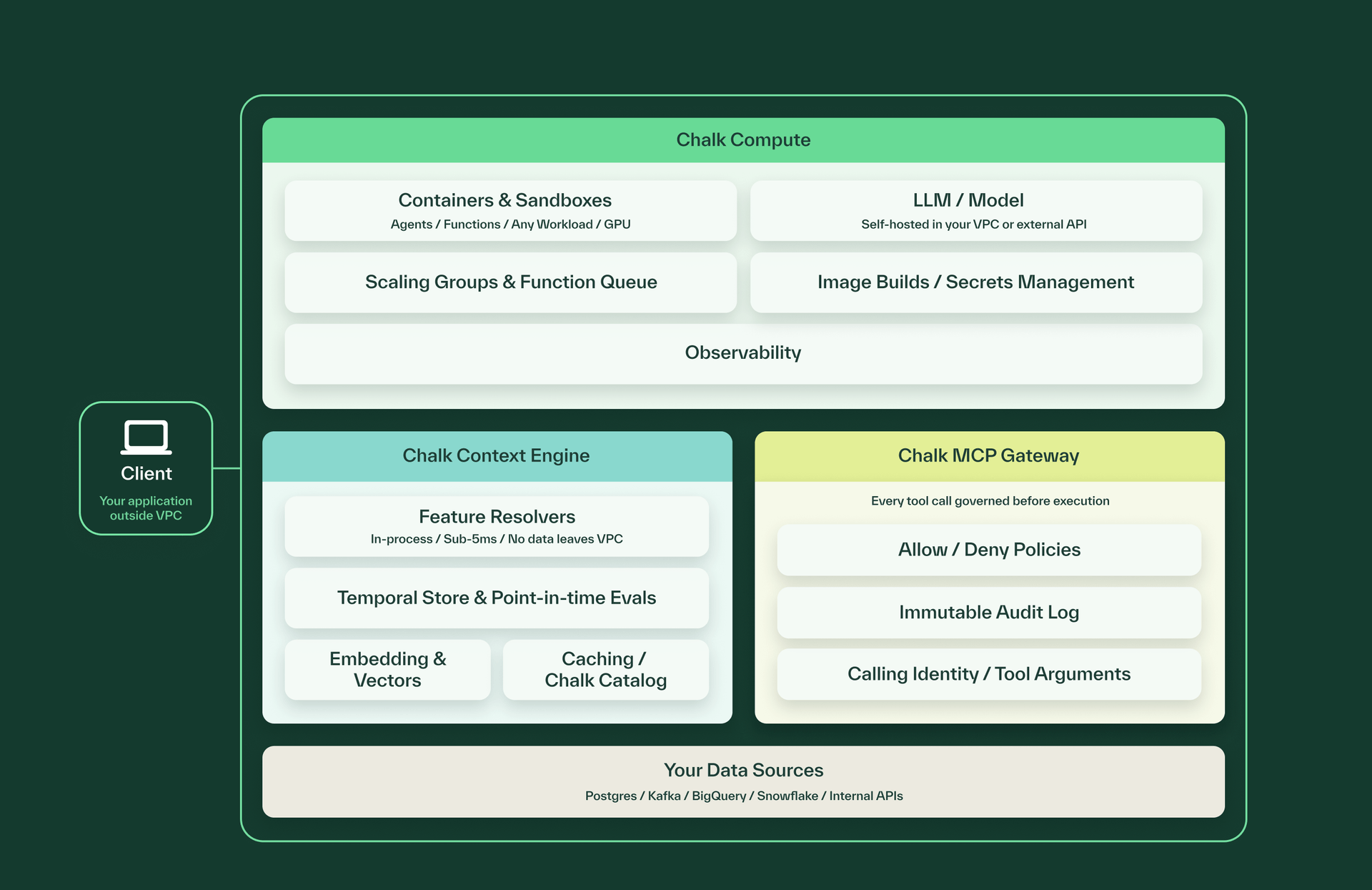
Chalk Compute is an enterprise-grade agent runtime that deploys sandboxes directly inside your private cloud.
Tightly integrated with the Chalk Context Engine, it makes it simple to run temporally consistent agent evals on your historical production data. A single “knowledge cut-off” parameter initializes your sandbox and routes every tool flow through the Chalk MCP gateway, locked to that point in time. As far as the agent knows, it's running in the past.
The Chalk Compute architecture is already hardened at production scale. We have spent years building production ML infrastructure for customers like MoneyLion, Whatnot, and Grindr. Grindr runs Chalk Compute directly in their cloud to orchestrate trust-and-safety workloads that protect more than 15 million users, and to run engineering pipelines where agents now handle 80% of internal code commits.
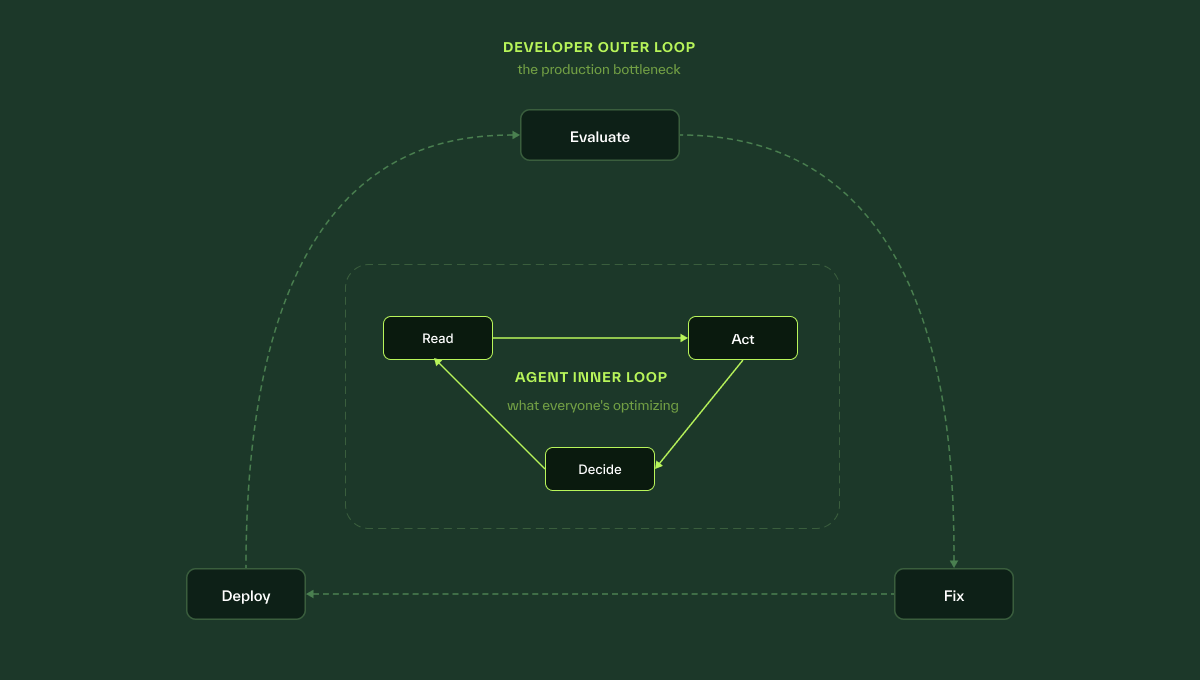
The industry is optimizing the wrong loop.
The broader AI ecosystem is locked in an infrastructure sideshow, racing to optimize the agent’s inner loop: making containers spin up marginally faster to read, decide, and act.
But for teams deploying real enterprise applications, the bottleneck isn't raw container execution speed. It is the developer's outer loop: evaluating an agent against real historical context, fixing prompts or tools, and redeploying with confidence that agents will behave as expected.
General-purpose runtimes force you to fabricate brittle synthetic test environments to guess at agent behavior. Because Chalk Compute sits natively on top of our real-time, temporally consistent context engine, it can deliver the counterfactual: how the agent would have behaved against the world it would have faced.
There’s a well-worn claim: all production application problems are database problems. Agents haven't changed this. Context engineering is a new name for feature engineering, which is a new name for data engineering.
The name changes, the job doesn’t: identify the signals that drive decisions, get them to the model instantly, and ensure they mean the same thing at training time that they do at inference time.
Chalk has been solving that problem for years before "agent" entered the vocabulary. Chalk Compute is the execution surface. The Chalk Context Engine is the substance.
The Chalk Context Engine: A Feature Store with a Memory
Most feature stores only serve the present. They capture the current state of a database or the latest log line, leaving developers to patch together historical data when testing or auditing applications manually.
The Chalk Context Engine serves the past as easily as the present. Every value it serves, whether it’s a customer’s transaction history, a fraud signal, or the output of a model call, is versioned by time. The Context Engine lets you ask, “What was this user’s score on March 14 at 3:42 PM?” and instantly get the same answer your production system would have served at that precise moment. This is what makes time-traveling agents possible.
And it’s fast. To make this data useful to enterprise-grade agents and models, delivery must be instantaneous. Chalk’s native Python resolvers connect your existing production data sources—including Snowflake, Databricks, BigQuery, Postgres, Kafka, internal APIs, and external SaaS vendors—to serve features with sub-5ms latency.
The Chalk Context Engine eliminates the need to build, scale, and maintain complex RAG retrieval pipelines or undergo massive data migrations. Your agents query live production data the same way your ML models do, against a temporally consistent view of your business state. We operate on a simple principle: your production data is your best training and evaluation environment.[1]
True Backtesting with Temporally Consistent Agent Trajectories
It’s important to understand how this differs from a traditional "as-of" query in a data warehouse. Those can give you point-in-time lookups on historical data. But they can’t control the agent's behavior.
When an autonomous agent executes a loop, it ultimately takes actions: querying internal services, running sandboxed code, or hitting external APIs. This series of sequential actions forms what we call an “agent trajectory.”
Every tool and data call your agent makes passes through the Chalk MCP Gateway. When a developer initializes a Chalk Compute sandbox with a knowledge cutoff, the MCP Gateway acts as an inline security and data governor.
It doesn’t just fetch old database records; it propagates time bounds to all downstream tools and APIs so that they respond as they would have at that specified moment in history. An agent executing a simulation or a replay test can never accidentally peek into the future.
By combining point-in-time consistency with active runtime enforcement, Chalk provides the only platform capable of executing truly time-locked, temporally consistent agent trajectories.
Chalk Compute: Closing the Outer Loop at Enterprise Scale
Chalk Compute deploys entirely within your private cloud. Your agents, your context queries, and your tool calls route exclusively through your own VPC infrastructure, never touching any third-party servers.
The platform automates the heavy lifting: container builds, image caching, autoscaling, and secret injection. Every sandbox runs under gVisor, a user-space kernel that intercepts syscalls before they reach the host. Outbound egress is locked to a hostname or CIDR allowlist you control. And it's fast: it scales to 10,000 isolated containers in under 10 seconds to handle massive concurrent agent workloads.
The platform delivers developer ergonomics without sacrificing enterprise security boundaries. Defining a secure agent sandbox and binding its entire downstream trajectory to a specific point-in-time requires nothing more than a little Python:
import chalkcompute
from chalkcompute import ChalkClient
# The sandbox sees the world as it was.
sandbox = chalkcompute.Sandbox(knowledge_cutoff="2025-09-15T14:30:00Z")
@sandbox.function(
image=chalkcompute.Image.debian_slim().pip_install(["openai"]),
secrets=[chalkcompute.Secret.by_name("openai-api-key")],
)
def investigate_refund(order_id: str) -> str:
# ChalkClient queries return the data as it existed at the cutoff.
risk = ChalkClient().query(
input={"order.id": order_id},
output=["order.refund_risk_score", "order.customer_prior_refunds"],
)
# Downstream external API calls through the MCP gateway are replayed from
# historical recordings and securely governed by policy
...
With this architecture, a simple Python decorator replaces hours of infrastructure overhead. You no longer need to write custom Dockerfiles, manage complex Kubernetes manifests, or handle cluster administration. You can swap an LLM framework, modify a tool payload, or adjust a prompt in plain Python without ever touching a deployment configuration file.[2]
Context Isn’t Simply a Compute Bolt-On
General-purpose container runtimes like Modal, E2B, or Daytona can spin up sandboxes in the cloud. But none of them can rewind the world your agents read from. They serve the present, or a snapshot you’ve manually assembled. There is no mechanism to lock an agent’s entire tool trajectory—every downstream API call, every LLM context window—to a consistent past moment. That’s an architectural gap that can’t be patched onto a generic runtime.
Attempting to recreate time-traveling agents on a generic runtime requires manually standing up an enterprise feature store, building a custom real-time retrieval layer, and engineering a stateful policy router to enforce knowledge cutoffs.
We have spent four years hardening that exact real-time data delivery engine for the world’s most demanding production ML environments. Data delivery is the hardest problem in enterprise AI. It is the one thing you cannot simply bolt onto a compute runtime after the fact.
Together, Chalk Compute and the Chalk Context Engine form the first unified AI data platform built for speed, hosted in your cloud, and designed to run autonomous agents against real-time and historical point-in-time data with absolute data sovereignty.
Grindr: What You Can Ship When the Data Doesn’t Move
When Grindr, already a Chalk Context Engine customer, started building agentic workloads, they needed a compute runtime to accelerate their developer outer loop. Their use cases span trust-and-safety agents, matchmaking agents turning multimodal user behavior into real-time recommendations, and internal engineering agents that now route 80% of the team's code commits.
Handling some of the most sensitive PII in consumer technology means Grindr’s infrastructure constraints are absolute. Any agent platform that routes user payloads through a vendor's third-party managed infrastructure is an immediate non-starter, regardless of the security guarantees offered. They needed a platform that could execute untrusted code, enforce strict data governance, and maintain complete end-to-end visibility without a single byte of data ever leaving their VPC.
Residency isn't the only hurdle at Grindr's scale. InfoSec review velocity is a major concern. Most agent platforms force a manual safety review for every new agent configuration or prompt change. This bottleneck scales linearly with deployments.
Chalk Compute shifts the unit of security from the individual agent to the platform: permissions, audit logging, and MCP routing all live at the gateway level, so InfoSec clears Chalk once inside the VPC, allowing developers to ship thousands of distinct agents without new review cycles.
Grindr Chief Product Officer AJ Balance describes the operational impact:
"Chalk Compute was the only integrated compute and context engine for agents that ran entirely inside our own environment, at the scale we needed, without becoming an infrastructure project. What would have taken months took weeks."
Run Your First Time-Traveling Agent
As the AI ecosystem matures from conversational chatbots to autonomous agents that actively manipulate business state, the critical architectural constraint has migrated from raw compute capacity back to data delivery. The teams that will define what agents can do in production are the ones who treat the data layer as load-bearing from the start.
By unifying a real-time, temporally consistent context layer with secure, in-VPC agent sandboxes, Chalk Compute allows engineering teams to stop fabricating brittle synthetic test environments and start shipping with absolute historical confidence. If the architecture holds for Grindr's data, it'll hold for yours.
If your eval set doesn't include the exact data your agent would have actually seen at inference time, it's time to fix your outer loop.
- Enterprise Availability: Chalk Compute is available today for customers running on AWS (EKS) and GCP (GKE), with support for Azure (AKS) coming soon.
- Open Source: This summer, we'll be open-sourcing the Chalk Compute runtime so engineering teams can inspect, extend, and run it themselves.
Reach out to our engineering team at chalk.ai/compute to get started.
- Because the Chalk Context Engine serves the same production signals to your training runs that your agents rely on at inference time, your proprietary data becomes your most powerful RL environment. More on this soon.
- If you need the model call to stay inside your VPC too, simply swap openai:gpt-4o for a self-hosted model running on Chalk Compute (Qwen, Llama, whatever you're running).




