

This quarter, we focused on strengthening the systems that keep Chalk fast and reliable in production. Updates to planning, monitoring, and integrations improve how teams scale heavy workloads, automate alerts, and manage real-time data pipelines.
Here’s what’s new.
Metaplanning and autosharding for large workloads
Chalk’s metaplanner now automatically determines how to shard scheduled offline queries based on input size and complexity. It splits large inputs into multiple smaller queries that the query planner can execute in parallel across available compute.
Previously, teams needed to decide shard counts ahead of time. The metaplanner now computes the optimal number of shards automatically, scaling compute to match workload size.
This makes feature recomputations faster, more efficient, and easier to manage. It improves runtime behavior and reduces operational overhead across high-volume jobs.

Get in contact with our team to enable metaplanning in your environment.
Runtime and planner performance improvements
We improved planner caching and parallel resolver execution to make query runtime faster and more consistent. Cold-start latency has been reduced, and repeated workloads now benefit from higher cache hit rates.
These changes help teams achieve lower latency and smoother performance during both development and production runs, especially when operating at scale.
Webhooks for real-time alerting and custom integrations
Teams can now configure webhooks directly in the Chalk dashboard to send alerts or trigger actions when events occur. Webhooks can be set up for scheduled queries, task completions, or deployment failures, and can integrate with tools like Slack, PagerDuty, and custom HTTP endpoints.
These webhook updates are part of broader monitoring improvements that include configurable alert rules and metric filters, helping teams fine-tune their observability and catch issues earlier.
This helps teams automate responses and maintain system reliability across environments.
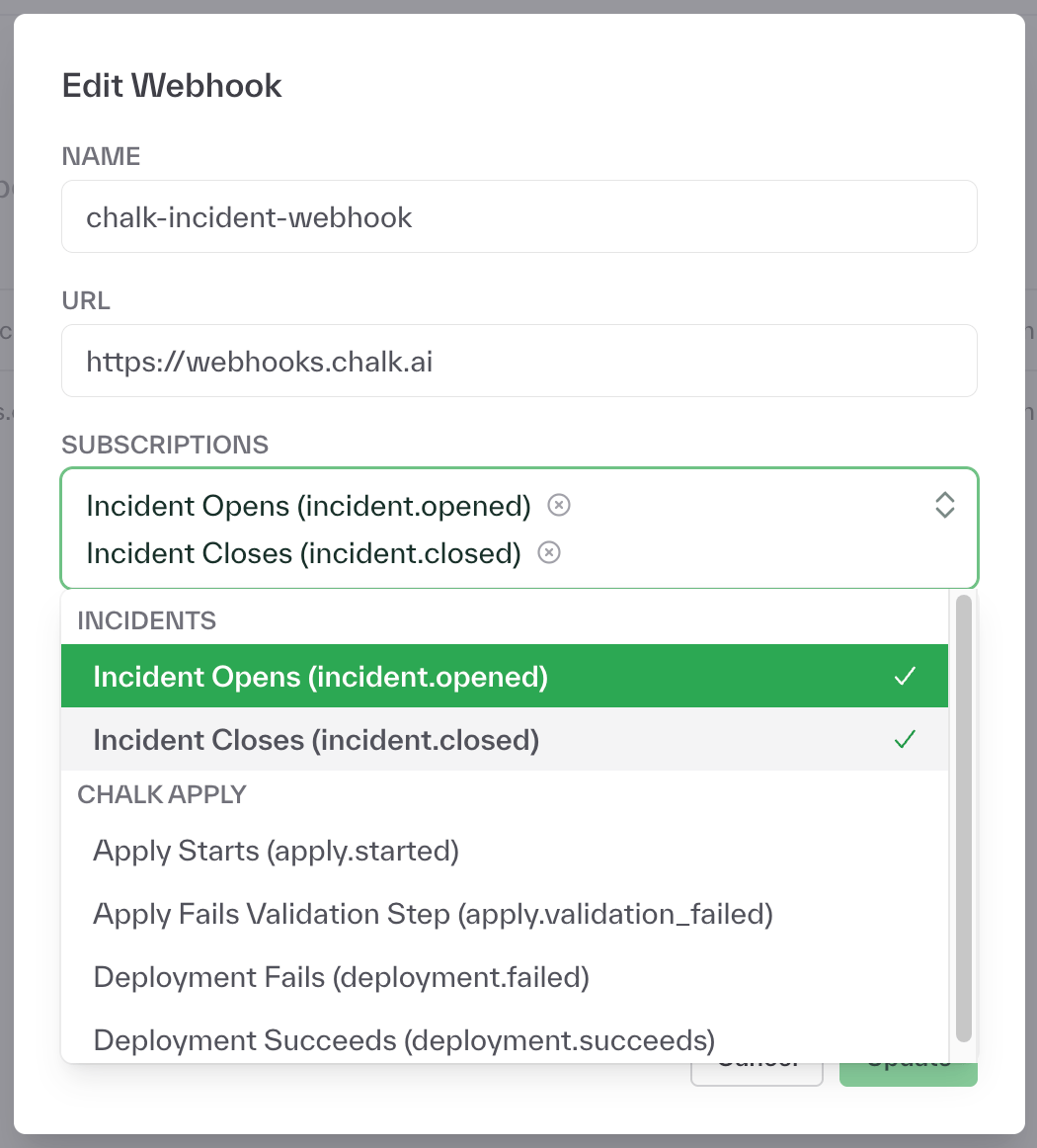
Learn more about Chalk’s latest webhooks.
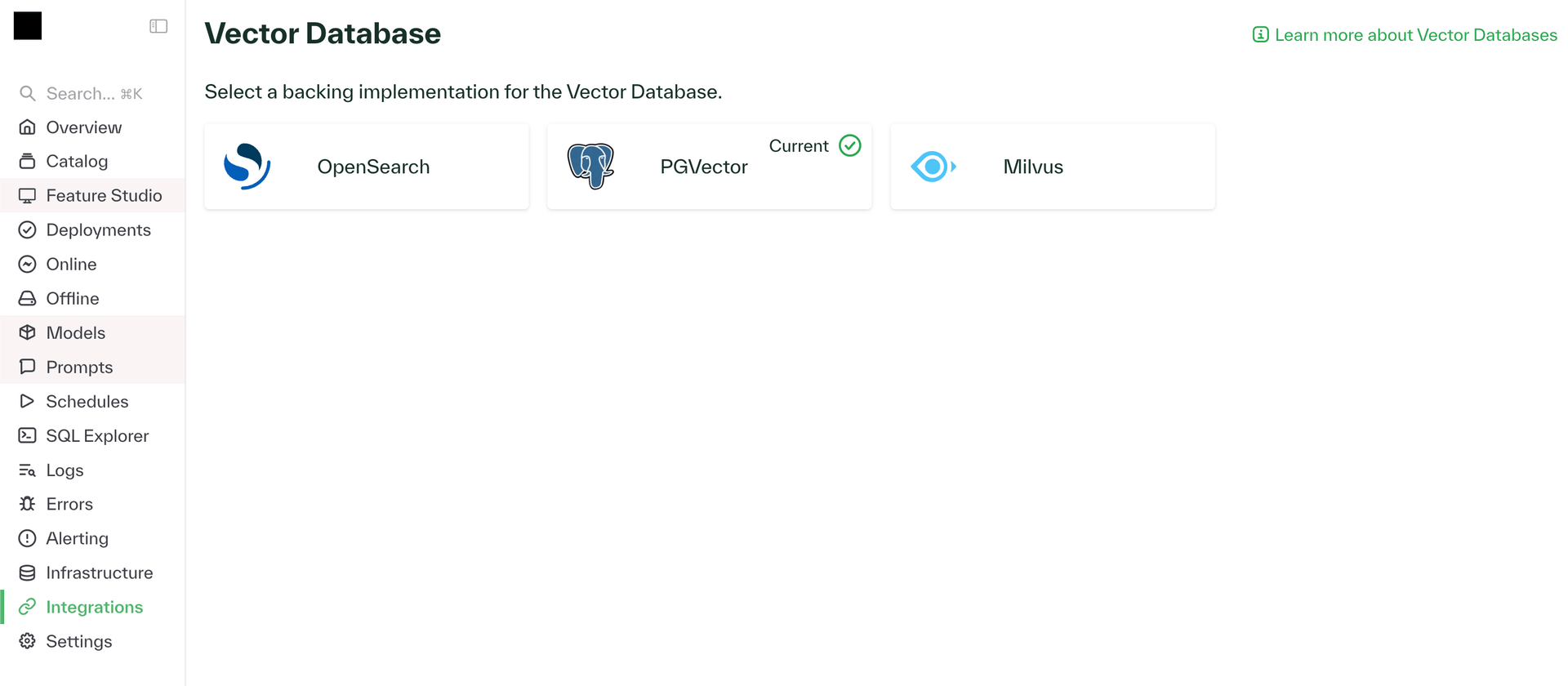
Connect vector databases from the dashboard
Chalk now supports registering external vector databases directly through the Integrations page. Once connected, teams can use these stores to power retrieval, personalization, and fraud detection models without leaving Chalk.
The dashboard supports registration, configuration, and health monitoring of the integration. This reduces setup complexity and expands Chalk’s ecosystem for embedding and similarity-based systems.
Learning and deep-dive resources
To help teams see how Chalk fits into production ML stacks, we partnered with customers to share their stories and expanded our content across the website and docs.
- New use case pages: Explore how Chalk powers real-time decisioning across different use cases.
- Fraud detection - Detect and prevent fake accounts and transactions using live features.
- Payments - Power authorization and risk decisions with fresh behavioral data.
- Underwriting - Deliver auditable credit decisions with fresh bureau and alternative data.
- Recommender Systems - Serve real-time recommendations that adapt instantly to user behavior.
- Search and Ranking - Rank results dynamically at query time using living context.
- Growth Decisioning - Power lifecycle and retention decisions with live engagement data.
- Chalk by team pages: Role-specific content and highlights for teams building and operating production ML:
- Data Engineers - Build real-time features without maintaining custom pipelines.
- MLOps - Operate production ML with full data lineage and reliable model inputs.
- ML Engineers - Ship low-latency inference systems that serve fresh data at scale.
- Data Scientists - Prototype and deploy features from notebooks with parity across training and serving.
- Customer story: We partnered with Medely to showcase how they use Chalk to power clinician matching in real time, optimizing for availability, credentials, and location across millions of jobs and professionals.
- Migration guide: We published a migration guide for teams moving from Tecton to Chalk. It walks through how to bring your existing features and pipelines into Chalk’s feature store platform. Learn how Chalk supports transitions from Tecton here.





